这篇paper是被Goldberg顺带怼过的一篇文章,也算是走红了。已有的文本生成工作具有不可控的属性,比如我不知道我下一句话生成的会是一个什么情感的句子。或者是什么时态的句子,这是机器人必须突破的限制。我的前端语义理解系统理解出来了用户可能需要一个positive的回复,但是我如何给呢?
这篇文章的主要思路是用类似GAN的方式,互相促进,同时把这个学习信号嵌入到Generator的一个位上。
Challenges
- 文本天然是一个离散的数据,导致两个网络之间的结果不可导。
- 另一个挑战是如何学习到一个disentangle representation。通过操作这个representation我们就可以操纵生成文本的某些特征。
Model Overview
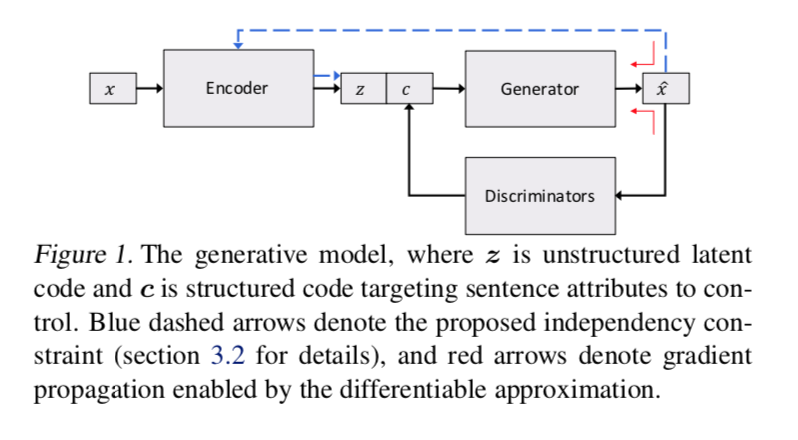
为了让representation没有指定语义和指定语义了的部分不纠缠在一起,于是将二者分开训练。
如图所示,框架从VAE开始。Encoder和Generator构成了一个VAE。中间的隐状态$z;c$是输入的表示。其中$c$表示的是生成的一些特征。为了学习这个$c$,本文提供了一个单独的discriminator来判断生成的句子的属性和$c$匹配的程度。为了让discriminator的结构能够反向传播到generator中,就需要让生成的句子以一个连续的表示出现。于是就用了一个continuous approximation based on softmax with a decreasing temperature。这个最终会退火到离散的表示。
这里面有两个loss,一个是让VAE能够encode和decode出相同的信息,另一个是用discriminator来监督$c$的生成。
但是实际上还增加了一个,就是将生成的样本再用encoder输出一个新的$z$,用这个$z$同原本的$z$进行比较。说是可以确保$z$和$c$的独立性。